Databases - System design concepts
A database management system is a software to store, organize,manage, and retrieve data.
1. Types of databases
1.1 Relational Databases
This database commonly uses Structured Query Language (SQL) for operations like creating, reading, updating, and deleting (CRUD) data.
This database stores data in discrete tables, which can be joined together by fields known as foreign keys. For example, you might have a User table that contains data about your users, and join the users table to a Purchases table, which contains data about the purchases the users have made. MySQL, Microsoft SQL Server, and Oracle are examples.
They are compliant with ACID (Atomicity, Consistency, Isolation, Durability), which is a standard set of properties for reliable database transactions.
1.2 Non-Relational(NoSQL) Databases
NoSQL is an umbrella term for any alternative system to traditional SQL databases. Sometimes, when we say NoSQL management systems, we mean any database that doesn't use a relational model. NoSQL databases use a data model that has a different structure than the rows and columns table structure used with RDBMS.
NoSQL databases are different from each other. There are four kinds of this database:
- document DB
- key-value store DB
- column-oriented DB
- graph DB
1.2.1 Document databases
A document-oriented database stores data in documents similar to JSON (JavaScript Object Notation) objects. Each document contains pairs of fields and values. The values can typically be a variety of types, including things like strings, numbers, booleans, arrays, or even other objects. A document database offers a flexible data model, much suited for semi-structured and typically unstructured data sets. They also support nested structures, making it easy to represent complex relationships or hierarchical data.
A typical document will look like the following:
1 | |
Document databases allow you to query information not just by the unique identifier (like the key in key-value databases) but also by the internal content. You can apply conditions or filters to your queries. For example, you can find all users within a certain age group or of a certain status.
Document databases also support aggregation operations (calculating, grouping, and summarizing data) and indexing (locating and retrieving documents based on the indexed fields).
- Examples: MongoDB, Amazon DocumentDB
- Use cases:
- Content Management Systems (CMS): Document databases allow for the storage of various content types and metadata. Each piece of content (e.g., blog post, article, or media file) can be stored as a document.
- User profiles: Document databases allow nesting, enabling you to store hierarchical or grouped data within a single document. This makes it easy to model complex user profiles that include details like order histories, preferences, or social connections.
1.2.2 Key-value databases
As the name suggests, key-value databases store data as pairs of keys and values. Each key is a unique identifier (like a name, ID, or reference number) and is associated with a value, which can be anything from a simple string to a more complex data structure, such as an object or a list.
A simple view of data stored in a key-value database is given below:
1 | |
Key-value databases are optimized for fast, efficient, and simple lookups by key, but they are limited when it comes to complex query operations.
- Examples: Redis, Amazon DynamoDB
- Use cases:
- Caching and session management: Key-value databases ensure quick access and updates for user session details such as authentication tokens, preferences, or temporary states.
- Storing basic information: Key-value databases are a straightforward solution for applications requiring simple data storage without complex relationships. For example, an eCommerce website can store shopping cart data, where the key is the user ID, and the value is the cart's content.
1.2.3 Column-oriented/wide-column databases
Сolumn-oriented (or wide-column) databases store data column by column rather than rows, organizing related information in column families. Unlike SQL databases, the structure of these columns doesn’t have to be consistent across rows. Each row within a family can have a completely different number of columns. This flexibility allows column-oriented databases to handle large amounts of data with varying schemas.
Below is an example of column-oriented database:

- Examples: HBase, Apache Cassandra
- Use cases:
- IoT systems:The massive volume of data generated by IoT devices, such as sensor readings and telemetry, is often stored in column-oriented databases. They can efficiently handle the high-write throughput and effectively store streaming data like temperature, humidity, and device statuses. Column-oriented databases also fit scenarios when you need to monitor manufacturing equipment and run predictive maintenance.
- Big data analytics and BI tools: By storing data in columns, queries can focus on specific sets of data, minimizing the amount of irrelevant information that must be read and making analytical queries faster and more efficient. For example, if you want to calculate the total sales per region, only the "sales" and "region" columns have to be accessed.
1.2.4 Graph databases
A graph database stores data in the form of nodes and edges. Each element is contained as a node. The connections between elements in the database are called links or relationships. They work well for highly connected data, where the relationships or patterns may not be very obvious initially.
Below is an example of how data is stored:
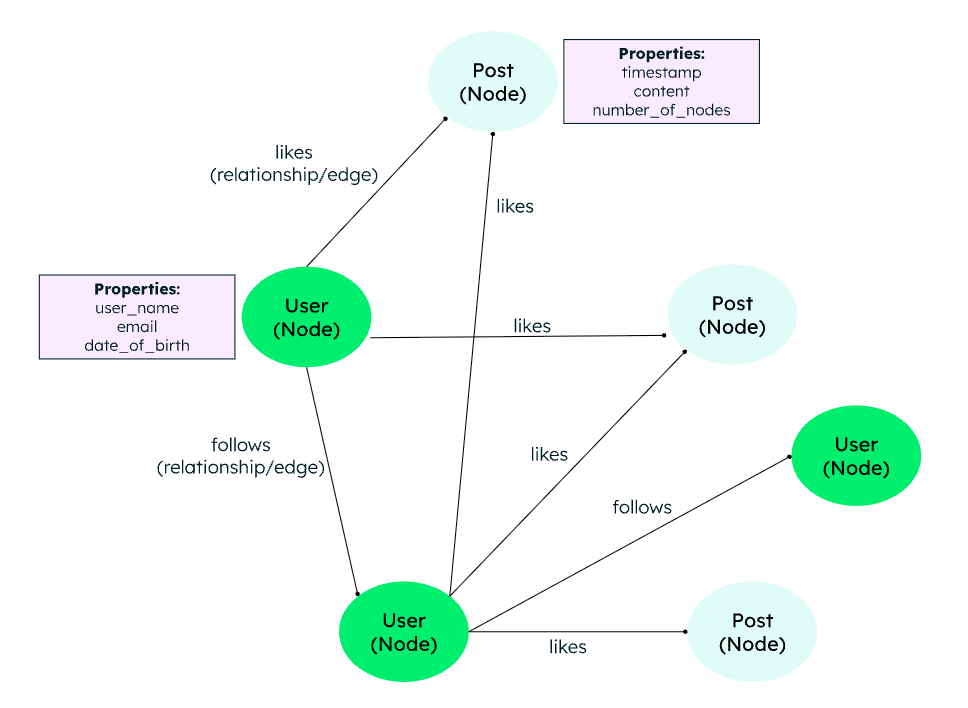
A graph database is optimized to capture and search the connections between elements, overcoming the overhead associated with JOINing several tables in SQL. Very few real-world business systems can survive solely on graph databases. As a result, graph databases are usually run alongside more traditional databases.
- Examples: Neo4J, Amazon Neptune
- Use cases:
- Social networks: Graph databases are commonly used in social networking platforms, where users are connected to other users through relationships like "follower" or "message sender." Graph databases make it easy to query for friends of friends, mutual connections, or any other complex social relationship.
- Recommender systems: Products, movies, or services can be traced to users through relationships like "purchased" or "watched," and the system can recommend items based on the connections and similarities between users and products.
- Fraud detection: Graph databases are powerful tools for fraud detection because they focus on analyzing relationships between entities such as people, accounts, and transactions. They can identify patterns and anomalies that suggest fraudulent activities, such as uncovering circular money movements used in money laundering or unusual relationships between accounts.
1.2.5 Multi-model databases
Multi-model databases support different ways of storing data (document, key-value, graph, and wide-column) within the same system. They allow applications to store data in the most convenient form, handling only one repository. For example, user data can be kept as documents and relations as graphs.
- Examples:
- Azure CosmosDB supports storing data in documents, key-value pairs, wide columns, and graphs. It’s compatible with MongoDB and Apache Cassandra and supports Apache Gremlin for querying graph data. It also allows for querying JSON data with an SQL-like language.
- AWS DynamoDB supports document and key-value models. It includes reliability features, such as managed backups (automatically or semi-automatically backing up data at scheduled intervals), point-in-time recovery (restoring a database to a specific moment in time), and more.
1.3 Hierarchical Databases
The hierarchical database looks similar to a family tree. A single object (the “parent”) has one or more objects beneath it (the “child”). No child can have more than one parent.
In exchange for the rigid and complex navigation of the parent child structure, the hierarchical database offers high performance, as there’s easy access and a quick querying time.
The Windows Registry is one example of this system.
2. Types of data processing systems
2.1 OLTP: Online Transaction Processing
It refers to systems that manage transactional data. Such data includes sales transactions (e.g., point-of-sale purchases), online orders, inventory updates, customer support interactions, and administrative updates like password changes or profile modifications.
Due to their structured nature, OLTP systems typically follow a traditional database schema for efficient organization and retrieval of data. They focus on high volume and high velocity because they are often utilized by front-line workers with customer-facing responsibilities.
OLTP Systems:
- MySQL
- Oracle Database
- PostgreSQL
- Microsoft SQL Server
2.1.1 Characteristics
- High concurrency: Handle thousands (or millions) of users performing transactions simultaneously. This can be like multiple stores processing sales at once.
- Real-time processing: Ensures instant updates to the system with each transaction
- Short transactions: Executes quick operations like adding, updating, or deleting records.
- Quick response times: Prioritizes speed to support time-sensitive processes. These systems often have millisecond response times.
2.1.2 Examples
- Online banking applications: These systems allow customers to manage deposits, withdrawals, and account transfers. Making sure these are as near real-time as possible is important. Even if transactions may not be fully processed for a few days, these transactions must show up immediately.
- CRM software: Tracks customer interactions for sales and support teams in real time, allowing them to create dynamic marketing and sales campaig
2.2 OLAP: Online Analytical Processing
It includes systems focused on analyzing large datasets, helping teams uncover patterns, trends, and insights for strategic decision-making.
They utilize a special data design known as the “OLAP cube,” which organizes data in multi-dimensional arrays for more straightforward “slicing” of data. As computational demand changes, there has been a shift away from the cube and towards MPP (Massively Parallel Processing).
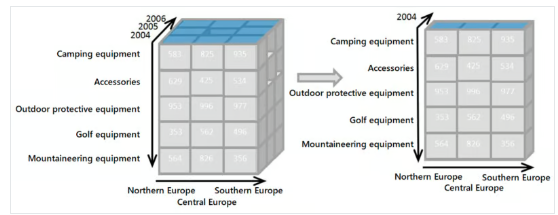
OLAP Systems:
- Amazon Redshift
- Snowflake
- Microsoft Azure Analysis Services:
2.2.1 Characteristics
- Multidimensional data structures: Organizes data into cubes, allowing for fast and flexible exploration across dimensions like time, geography, or product category.
- Complex queries: Executes sophisticated queries that often span large datasets. Collecting these complex queries is effective and straightforward, using the multidimensional data structure.
- Historical data analysis: This technique combines current and historical data to generate insights. Time is a common axis in the OLAP cube, so traversing through time for historical data is simple.
- Business intelligence support: Powers dashboards, reporting tools, and predictive analytics.
2.2.2 Examples
OLAP systems tend to focus on data availability. These are going to be things like data warehouses, dashboards, and analytical tools.
- Data warehouses: Centralized repositories for aggregating data from multiple sources, often including OLTP systems. They enable efficient querying and analysis of large datasets.
- Business intelligence dashboards: Provide visual analytics for performance metrics. By combining OLAP with powerful visualization tools, we can quickly and intuitively understand business performance.
- Sales analysis tools: Help forecast trends and evaluate profitability.
2. Features of databases
2.1 Compliance
2.1.1 ACID
ACID compliance refers to a set of properties (Atomicity, Consistency, Isolation, Durability) that guarantee reliable, correct, and safe execution of database transactions — ensuring data stays accurate and consistent even in cases of errors, crashes, or concurrent access. It's used in relational databases, and some NoSQL databases like MongoDB.
ACID stands for:
- A (Atomicity): Transactions are treated as a single unit - so if one action fails, the whole transaction fails.
- C (Consistency): The database must remain in a consistent state for a transaction to succeed
- I (Isolation): Simultaneous transactions do not affect the outcome of one another.
- D (Durability): Once a transaction is completed, it will persist even in the event of a system crash
Common use cases:
- Banking and financial systems
- Order processing (e-commerce, ticketing)
- Inventory management
- Anything where data integrity is critical
2.1.2 BASE
BASE compliance refers to a set of principles used in NoSQL and distributed databases that prioritize availability, scalability, and flexibility over immediate consistency. It allows systems to remain responsive and partition-tolerant by accepting eventual consistency instead of enforcing strict rules like ACID.
BASE stands for:
- BA (Basically Available): The system will always be available for reads and writes, even if some parts of the system are down.
- S (soft state): The system’s state can change over time, even without input, due to eventual consistency.
- E (Eventually consistent): The system will eventually converge to a consistent state, but it’s not guaranteed immediately after a write.
Common use cases:
- Real-time analytics
- Logging or event tracking
- Caching systems
- High-throughput systems where eventual consistency (like in NoSQL) is acceptable